Если используется стратегия параметризации, то анализ опускается на второй слой. В случае табличного шардинга вызывается третий слой межкластерной индексации. Этот подход даёт преимущество практически линейного масштабирования производительности. Особенно на логически несвязанных между собой данных, таких, как база данных клиентов. Для каждой части данных на выделенном сервере есть свои независимые процессоры и память. Накладные расходы на поиск шарды, где хранится или должна быть сохранена информация, на практике слабо зависят от степени дробления.
Распределенная Субд Shardman: Горизонтальное Масштабирование Для Enterprise-задач На Базе Postgres Pro
Для оптимизации работы операций JOIN с большими таблицами вы можете задать ключ дистрибуции явным образом. В таком случае при соединении таблиц по указанным в ключе полям операция будет производиться локально на сегменте, и запрос отработает быстрее. Шардирование – это мощный, но непростой способ заставить вашу систему справляться с огромными объемами данных и нагрузок. Это не волшебная таблетка, которую выпил и все заработало.
По сути, это разделение таблицы на логические части (партиции) для ускорения запросов и управления большими объемами данных. Если речь идёт о работе облачной системы, например, по автоматизации бизнес-процессов, то здесь в качестве ключа шардирования можно взять и организацию. Но компания компании рознь, ведь организации отличаются по размеру и количеству пользователей. Присваивая организации определенный сервер, мы заранее не знаем, насколько она вырастет. А если компания использует сервис очень активно, может наступить момент, что её данные не будут вмещаться на один сервер, следовательно, придётся делать решардинг.
Идеально подходит для приложений, где равномерное распределение данных является критически важным, например при хранении пользовательских сессий в веб-приложениях. MongoDB — это NoSQL хранилище данных, крайне удобное для хранения информации, которая не может быть нормально структурирована в рамках реляционных баз данных. MongoDB — это СУБД с открытым исходным кодом, не требующая описания схемы таблиц. Документы в MongoDB хранятся в JSON или BSON, работа с такой моделью проще кодируется и проще управляется, а внутренняя группировка релевантных данных обеспечивает дополнительный выигрыш в быстродействии. Репликация — это синхронное или асинхронное копирование данных между несколькими серверами.
- Для Диска в качестве ключа шардирования выбрали хэш от ID пользователя.
- Для плавного решардинга, без перерыва в работе вам придётся организовать оркестратор, который будет производить блокировку и разблокировку, а также добавлять признак того, что запись в процессе миграции.
- Благодаря такой архитектуре репликации мы получили надежное и быстрое хранилище.
- Например, часть старых пользователей перестаёт делать заказы, тогда как новые более активно заказывают.
Компоненты Менеджера Кластера¶
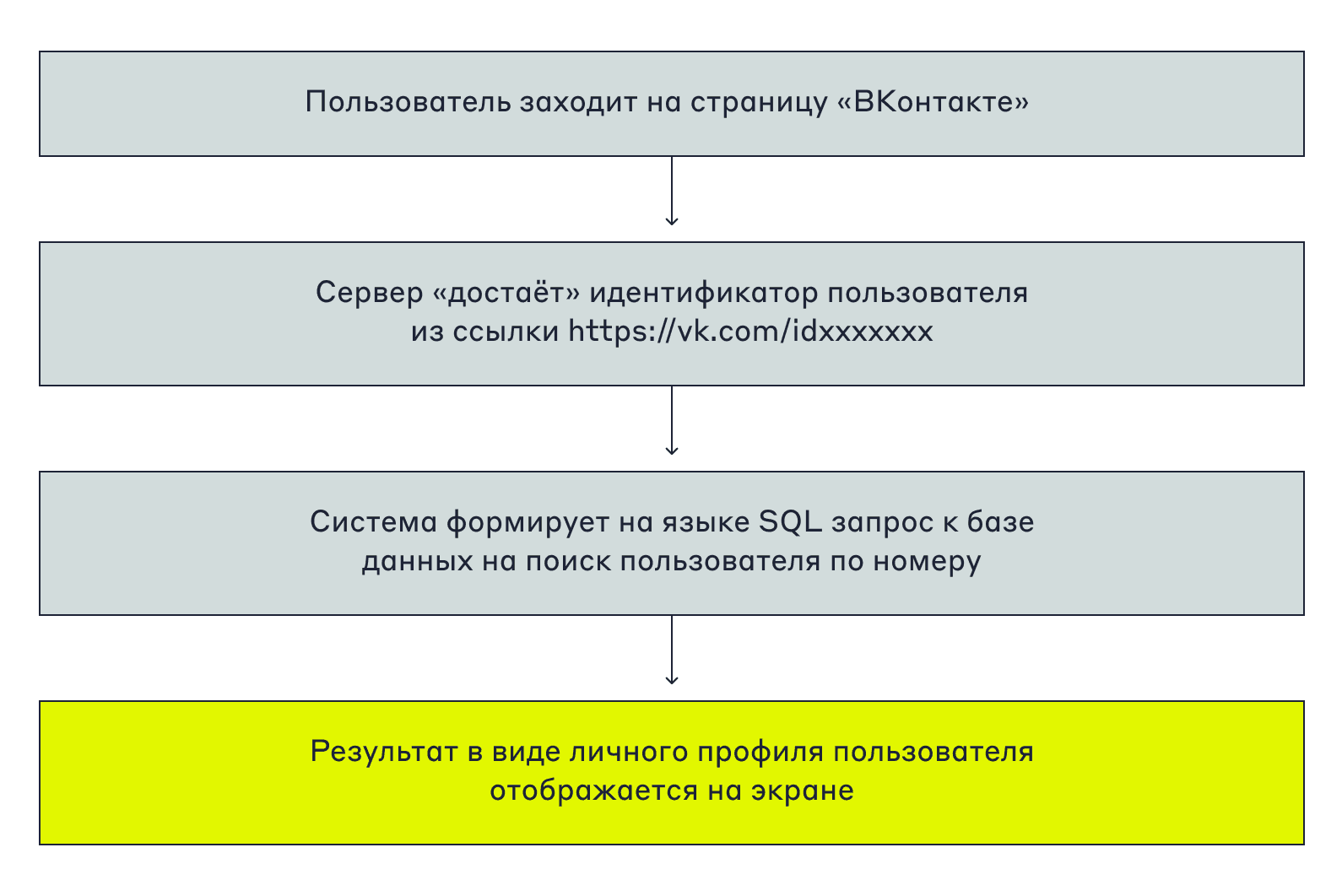
Они связаны с децентрализацией и с доступностью данных, поскольку Layer 2 имеют дело с большим количеством транзакций. Диск прошел долгий путь от коробочного решения MongoDB, которое шардировалось дефолтным способом, к текущей инсталляции с ручным шардированием. Само ручное шардирование тоже прошло много этапов — от шардирования на уровне воркера до микросервиса, который работает сейчас. System DB — это база данных с одной коллекцией, которая содержит только ID пользователя и ID-шарда.
С технической точки зрения Яндекс Диск — не просто веб-обертка файловой системы, а 60+ сервисов для обработки сотен различных фич — от просмотра и редактирования данных до публичного доступа к ним. Эта статья будет полезна, если вы планируете распределить нагрузку на вашу БД или вам просто интересен опыт развития БД для обработки большого числа запросов. Рост числа ядер не дает линейного прироста, а стоимость серверов с большим количеством ядер становится непропорционально высокой. В конечном итоге планируем прийти к тому, что при минимальной избыточности оборудования потеря одного ЦОДа не будет заметна пользователям. Репликация на уровне СУБД не понадобится — ее будет осуществлять Application Router.

Меня зовут Денис Иванов, и я расскажу о масштабировании баз данных через шардирование и партиционирование. После этого доклада у всех должно появиться желание что-то попартицировать, пошардировать, вы поймете, что это очень просто, оно никак жрать не просит, Финансовый риск работает, и все замечательно. Как рассказал, сам Андрей, в переводе с английского «шард» – это осколок.
Каждый запрос на запись или чтение в Greenplum® шард утилизирует все сегменты кластера. Несмотря на сложности, шардинг является важнейшим инструментом в арсенале архитекторов баз данных, особенно в сфере больших данных и приложений с высоким трафиком. Поскольку объем и значимость данных продолжают расти, шардинг будет оставаться жизненно важной стратегией для эффективного и результативного управления базами данных. Ведущие серверы используются для чтения и изменения данных, а ведомые — только для чтения. Однако в более сложных схемах репликации может быть и несколько мастеров.
Только когда количество запросов возвращалось к нижней планке, мы снова начинали выдавать тикеты. Когда у кого-то из пользователей становилось слишком много данных, их нужно было переносить с одного шарда на другой — более свежий, с большим количеством свободного места. Но провернуть такое в MongoDB из коробки можно было только с помощью секретного скрипта, который переносил данные для одного значения ключа с шарда на шард. Архитектура N-ЦОД подразумевает такое разделение данным между небольшими ЦОДами, что потеря одного любого https://www.xcritical.com/ из них не приведёт к потере данных.
